您好!欢迎登陆hy3380海洋之神线路网上娱乐官网!
hy3380海洋之神线路网上娱乐 | 产品中心 | 工程案例 | 联系我们 
您好!欢迎登陆hy3380海洋之神线路网上娱乐官网!
hy3380海洋之神线路网上娱乐 | 产品中心 | 工程案例 | 联系我们



The company covers an area of 50 mu and is located in the west of the Yangtze river. It has 350m long coastline, the standard E channel wharf, the starting point and the entrance of the G15 expressway in the east of the Yangtze river. The traffic is very convenient.
公司占地50亩,西临长江,拥有350m长水岸线,标准E级航道码头,东临长江北路高架路起点及G15高速公路入口,交通十分便利。

The company insists on the science and technology as the driving force, creates the core competitive advantage, has several steel market and many sand stone production line. Diversified products to meet the needs of different customers.
公司现有2000吨的货轮,6条砂石生产线,多个钢材市场,多元化的产品,满足不同客户的需求

Based on the service, quality is the survival and technology development.
尊重客户,理解客户,持续提供超越客户期望的产品与服务,做客户们永远的伙伴。这是我们一直坚持和倡导的服务理念。
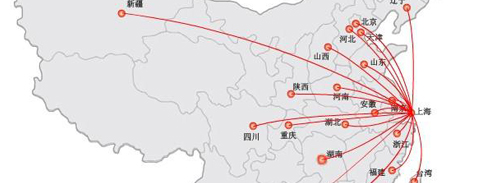
Sales and service network throughout the country 30 provinces, municipalities and autonomous regions
积极开拓国内外市场,以优质的质量和完善的服务赢得广大顾客的肯定和好评。

扫一扫更多精彩尽在手机网